Apache-projektet, som drivs av The Apache Software Foundation, är helt klart mest kända för sin marknadsdominerande webbserver (67% av marknaden i januari 2004). De flesta som utvecklar i Java är också väl bekanta med Jakarta-projektet som fungerar som ett paraply över en mängd av Java-projekt under Apache.
I den här artikeln kommer vi att gå igenom de flesta av Apaches Java-projekt. Syftet är att få fler att få upp ögonen på vilken hög med guldklimpar som rymmer sig där… Ja, rena guldgruvan, faktiskt!
Denna artikel är även publicerad i Datormagazin nr 11, 2003.
Inledning
Apache-projektet, som drivs av The Apache Software Foundation, är helt klart mest kända för sin marknadsdominerande webbserver (67% av marknaden i januari 2004). De flesta som utvecklar i Java är också väl bekanta med Jakarta-projektet som fungerar som ett paraply över en mängd av Java-projekt under Apache.
I den här artikeln kommer vi att gå igenom de flesta av Apaches Java-projekt. Syftet är att få fler att få upp ögonen på vilken hög med guldklimpar som rymmer sig där… Ja, rena guldgruvan, faktiskt!
Underprojekten i Apache är av väldigt olika omfattning och inriktning. Det enda som de projekt vi ska titta på i den här artikeln egentligen har gemensamt är nog det faktum att de är skrivna i Java, och att de oftast är relaterade till servertillämpningar i Java. Utrymmet i en artikel är begränsat, därför måste vi ibland bara med några ord sammanfatta projekt som det ligger åtskilliga manmånader eller -år bakom, men förhoppningen är att det ska locka läsaren till att söka mer information om projekt som verkar intressanta.
Det viktigaste Apache-projektet för Java-utvecklare är alltså Jakarta. Jakarta är ingen egen produkt utan fungerar bara som ett samlande namn på drygt tjugo Java-projekt! Vi kommer alltså att till största delen behandla olika underprojekt till Jakarta, men under Apache finns även andra projekt som är viktiga för Java-utvecklare, och vi kommer att gå igenom några av dessa också.
En framgångsfaktor hos Apache-projekten är att deras öppna källkod är släppt under en licens som gör att koden kan inte bara studeras av alla utan också användas av vem som helst till vad som helst.
De tre stora
De flesta som utvecklat serverprogramvara i Java har redan stött på några av Apache-projekten. Det finns framför allt tre av dessa som sticker ut lite extra, och som väldigt många känner till: Tomcat, Ant och Struts. Om dessa projekt finns det hur mycket information som helst att hämta på internet och i bokform, så vi kommer bara att nämna dem kortfattat i den här artikeln. Troligen får vi anledning att återkomma till dem i mer utförliga artiklar senare!
Tomcat
Tomcat är egentligen ”bara” referensimplementationen av Javas servlet– och JSP-specifikationer. Naturligtvis kan den leverera statiska filer via HTTP också, vilket innebär att den även fungerar som en Java-baserad webbserver. Servlets och JSP är centrala tekniker i servertillämpningar i Java. Detta gör Tomcat till en väldigt viktig applikation, och eftersom dess licens tillåter detta så dyker den ofta upp som komponenter i andra system – både sådana som själva är open source, men även produkter med sluten källkod.
Ant
Ant är ett exempel på projekt som tidigare legat i Jakarta, men sedan blivit så framgångsrika och generellt applicerbara att de ”befordrats” till ett eget Apache-projekt, på samma nivå som Jakarta och Apaches webbserver.
Ant är ett verktyg för att i första hand hantera byggprocesser i Javaprojekt. Jag säger ”i första hand” eftersom det visat sig att Ants extremt utbyggbara arkitektur gjort att tillägg har dykt upp för en stor mängd användningsområden, till exempel körning av enhetstester, synkning med versionshanteringssystem, hantering av applikationservrar etc.
För er som känner till det i unix-världen vanliga make-kommandot, är det enkelt att se Ants likheter. Make är dock inte helt tillfredsställande i Java-miljö av olika skäl, medan Ant är helt anpassat efter denna miljö. Själva byggfilen är till exempel skriven i XML vilket gör att man lätt känner igen sig, och underlättar för andra att integrera Ant i större utvecklingsmiljöer. Ett utmärkt exempel på detta är Eclipse som kommer med ett bra inbyggt stöd för Ant.
Struts
Struts är ett ramverk för att implementera en servlet/JSP-applikation med hjälp av designmönstret Model/View/Controller. Med hjälp av Struts kan du få en bra struktur på hur en webbapplikation hänger ihop, med bra separation mellan presentationsskiktet i JSP-sidor och logiken i Java-objekt.
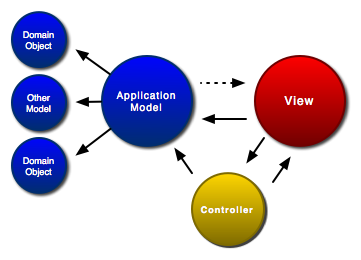
Den senaste versionen av Struts (1.1) innehåller förutom själva MVC-implementationen en hel del trevliga nyheter som till exempel valideringsramverk, deklarativ undantagshantering etc.
Webbrelaterade projekt
ECS
Innan JSP kom implementerades webbapplikationer bara med hjälp av servlets. En servlet innehöll då typiskt en stor mängd anrop av typen out.println("
För att underlätta HTML-genereringen från en servlet kan man använda Jakarta ECS (”Element Construction Set”). Med ECS kan du på ett programmatiskt sätt generera HTML-elementen. På så sätt garanteras det att starttaggar matchar sluttaggar, och så vidare.
En enkel användning kan se ut så här:
Html html = new Html()
.addElement(new Head()
.addElement(new Title("Exempelsida")))
.addElement(new Body()
.addElement(new H1("Demorubrik"))
.addElement(new H3("Underrubrik:"))
.addElement(new Font().setSize("+1")
.setColor(HtmlColor.WHITE)
.setFace("Times")
.addElement("Här är det lite text.")));
out.println(html.toString());
ECS är ett enkelt hjälpbibliotek som löser uppgiften bra, om du vill använda modellen ovan med HTML-generering direkt från servlets. Dock känns det som om den modellen är rätt åldersdigen, i och med att servlets och JSP numera fungerar väldigt bra tillsammans. JSP är överlägset för ”generering av HTML”, speciellt eftersom det finns många HTML-editorer som också har bra stöd för JSP. Utvecklingen av ECS verkar också ha avstannat sedan december 2000.
Taglibs
Sedan JSP version 1.2 släpptes har det varit möjligt för utvecklare att göra egendefinierade JSP-taggar, med godtycklig funktionalitet. Detta är en väldigt kraftfull egenskap i JSP, som väldigt bra hjälper till att separera funktionalitet från användargränssnitt. I projektet Taglibs finns drygt tjugo olika bibliotek med egna taggar, för att lösa specifika problem. De kapslar till exempel in det mesta av den information som finns direkt tillgänglig i en JSP-sida (request/response-information, sessionsvariabler, etc). Dessutom finns taggar som stödjer mer J2EE-relaterad funktionalitet, som till exempel JNDI, JavaMail, JMS och så vidare.
Följande lilla exempel visar en JSP-fil som använder sig av Taglibs-biblioteken DBTags och Mailer för att ta fram en person från en databas och skicka ett e-postmeddelande till honom.
<%@taglib uri="http://jakarta.apache.org/taglibs/mailer-1.1" prefix="mt"%>
<%@taglib uri="http://jakarta.apache.org/taglibs/dbtags" prefix="sql"%>
<sql:connection id="conn1" dataSource="PersonsDataSource"/>
<sql:statement id="stmt1" conn="conn1">
<sql:query>
SELECT email FROM Person WHERE userId='ture_test'
</sql:query>
<sql:resultSet id="rs1">
<mt:mail to="<sql:getColumn position="1"/>"
from="taglibs-experten@dinfirma.se"
subject="Testmeddelande">
<mt:message>Hej! Här får du ett mejl!</mt:message>
<mt:send/>
</mt:mail>
</sql:resultSet>
</sql:statement>
<sql:closeConnection conn="conn1"/>
Den troligen viktigaste medlemmen av Taglibs är dock referensimplementationen av JSTL (JSP Standard Tag Library). Från och med version 2.0 av JSP kommer alltså JSP att inkludera ett standard-tagg-bibliotek med stöd för vanliga uppgifter som slingor och villkor, och precis som att Tomcat fått förtroendet att vara referensimplementationen för JSP- och servlet-specifikationerna, så har Taglibs-projektet fått motsvarande förtroende för JSTL.
Velocity
Det finns många sätt att generera HTML… I Java-världen är ju JSP dominerande, men det finns faktiskt en del alternativ. En av de mer framgångsrika alternativa webbgränssnittsmotorerna är Velocity. Velocity är en generell mallmotor som även kan användas för att generera till exempel SQL, källkod eller annat.
Precis som JSP eller PHP (som för övrigt är ett annat Apache-projekt) kan Velocity-mallar innehålla en blandning av statisk HTML och dynamiska element, eller skript-kod. Velocitys skriptspråk ligger på en hög nivå och är väl anpassat till uppgiften att generera text i mallar och kan också lätt anropa kod skriven i ren Java.
Om du är Java-utvecklare och inte vill ”börja om från början” med att lära dig PHP, men vill ändå ha ett skriptspråk på en lite högre nivå så kan nog Velocity vara intressant att ta en titt på.
XML-relaterade projekt
FOP
Det numera vanligaste filformatet som stödjer snygga utskrifter är Adobes PDF (Portable Document Format). PDF är visserligen ett öppet format i betydelsen att det är lättillgängligt och dokumenterat, men det ”ägs” ändå av Adobe, som förstås helst ser att man använder sig av deras verktyg för att skapa och läsa PDF-filer.
Men det finns alternativ! Ett av dessa är en standard som tagits fram av World Wide Web Consortium, och helt enkelt kallas för ”Formatting Objects”, eller XSL-FO, eftersom det är en del av XSL-specifikationen. Precis som PDF så beskriver XSL-FO (eller bara ”FO”) ett format som beskriver hur en sida ska se ut, med en sån noggrannhet att den kan användas för riktiga utskrifter.
Tyvärr finns det, till skillnad från PDF, inte så många program som kan visa eller direkt skriva ut FO-dokument… Det är här som Apaches FOP-projekt kommer in! FOP står för ”Formatting Objects Processor” och är helt enkelt ett Java-program som kan konvertera ett FO-dokument till en mängd olika dokumentformat, som till exempel PostScript, RTF, MIF, och inte minst, PDF!
Man förstår snabbt att FOP lätt kan integreras i ett Java-program och användas för att generera PDF-filer för utskrift. Det gör man enklast genom att generera den information man vill skriva ut på ett strukturerat sätt i en XML-fil. Sedan konverteras XML-filen, via XSLT, till en FO-fil (som också är ett XML-format). Denna FO-fil matas sedan till FOP som skapar en PDF som levereras till användaren för utskrift.
Naturligtvis behöver man inte mellanlagra informationen i fysiska filer på hårddisken. I beskrivningen i förra stycket är det antagligen bara XSL-mallen (som beskriver hur det genererade dokumentet ska se ut) som faktiskt lagras på hårddisken.
<?xml version="1.0" encoding="utf-8"?>
<fo:root xmlns:fo="http://www.w3.org/1999/XSL/Format">
<fo:layout-master-set>
<fo:simple-page-master master-name="simple"
page-height="29.7cm" page-width="21cm"
margin-top="1cm" margin-bottom="2cm"
margin-left="2.5cm" margin-right="2.5cm">
<fo:region-body margin-top="3cm"/>
<fo:region-before extent="3cm"/>
<fo:region-after extent="1.5cm"/>
</fo:simple-page-master>
</fo:layout-master-set>
<fo:page-sequence master-reference="simple">
<fo:flow flow-name="xsl-region-body">
<fo:block font-size="12pt"
font-family="sans-serif"
line-height="15pt"
space-after.optimum="3pt"
text-align="left">
Enklast möjliga FO-sida! (exempel)
</fo:block>
</fo:flow>
</fo:page-sequence>
</fo:root>
Kodlistningen ovan är ett exempel på ett (väldigt enkelt, men komplett) FO-dokument. Först deklareras(i elementet fo:layout-master-set) hur sidan ska vara uppbyggd, med marginaler och utrymme för sidhuvud och sidfot. Sedan kommer innehållet i etttextflöde (fo:flow), som byggs upp av en mängd textblock(fo:block). I vårt exempel är det dock bara ett block. Ni som tidigare använt er av Cascading Style Sheets i HTML känner igen många av attributen.
Xerces/Xalan
Även om man är skeptisk till den hype som XML (och dess syskonspecifikation XSL) har fått de senaste åren så går det inte att komma ifrån att XML ofta ingår i moderna utvecklingsprojekt. För att läsa in, och ändra i, XML-filer behövs en bra XML-parser. Det är här som Xerces (XML-parser) och Xalan (XSL-tranformerare) kommer in.
Det är inte osannolikt att du redan använt dig av Xerces och Xalan. Om inte direkt, så åtminstone via någon av de andra Apache-projekten som till exempel ”de tre stora” som jag nämnde inledningsvis (Tomcat, Ant och Struts). Inget av dessa skulle fungera utan en bra XML-parser!
Xindice
Xindice är ett projekt som har ett tacksamt lättbeskriven funktion: det är en databas för att lagra XML-baserad data, det vill säga vad som vanligen kallas för en ”XML-databas”. Xindice är inte, och försöker inte heller vara, en ersättare till andra typer av databaser. Projektet är inte ute efter att ändra på det sätt som data generellt lagras, bara erbjuda en bra lösning för att lagra XML-baserad data. Om du gör en översikt av ditt projekt och upptäcker att data i XML-format dyker upp på fler och fler ställen kan Xindice ge dig stor hjälp att lagra och hantera den informationen.
Jakarta Commons
Det finns idag en hel uppsjö av användbara komponenter i olika konstellationer och från olika organisationer. Tyvärr är ofta dessa komponenter antingen designade för väldigt speciella ändamål eller så är de helt enkelt komplexa och tunga att börja använda. Projektet Jakarta Commons är en trevlig motsats till detta. Commons-projektet består av ett antal mindre och väl avgränsade komponenter som man kommer igång med på kort tid. Många av komponenterna i projektet härstammar från större komponenter i Jakarta, som till exempel Struts, där de blivit utbrutna när de visat sig återanvändbara. Commons är uppdelad i två delar: Proper och Sandbox, där Sandbox är en ”sluss” för komponenter under utveckling som inte blivit stabila nog eller på annat sätt inte är mogna för ”proper” användning. Vi avgränsar oss nedan med att fokusera på några av komponenterna i proper-delen.
Beanutils
Kombinationen JavaBeans och reflection i Java-världen möjliggör en hel smarta lösningar. Problemet är ofta att reflection och introspection-bitarna i JavaBeans är rätt så besvärliga att förstå sig på. Det är förstås här som BeanUtils dyker upp och underlättar livet en hel del genom att ta hand om just reflection, introspection samt syr ihop det hela på ett snyggt sätt med ”enkla, rakt på” metoder som gör att jag som utvecklar inte fastnar i reflection-labyrinten utan kan koncentrera mig på att bygga mitt system. Användningsområdena är många men normalt använder man BeanUtils för att möjliggöra dynamisk åtkomst mot JavaBeans-objekt, till exempel applikationens objektmodell.
Tag-biblioteket ”logic” i Struts och den väldigt användbara komponenten Digester använder BeanUtils friskt. Kodlistningen nedan visar ett exempel som genererar utskriften: Lokalen heter: PartyLadan och ligger i Östersund.
// Ok, vi skapar ett PartyLocation objekt som exempel
Address adr = new Address("PartyLadan","Storgatan 12","123 45","Östersund");
PartyLocation partyLadan = new PartyLocation("PartyLadan",adr,250,true,8000);
try {
// Här använder vi den enkla varianten.
String name = (String) PropertyUtils.getSimpleProperty(partyLadan, "name");
// Här använder vi den s.k. nested varianten för att nå ner i adress objektet.
String city = (String) PropertyUtils.getNestedProperty(partyLadan, "address.city");
System.out.println("Lokalen heter: "+name+" och ligger i "+city);
} catch {}
DBCP (DataBase Connection Pool)
Idag när man bygger Java-applikationer behöver man sällan bidra med egna poolningsmekanismer då dessa oftast hanteras av applikationsservern eller det ramverk man byggt sin applikation kring. Skulle dock behovet finnas från till exempel en fristående Java-applikation så kan DBCP vara intressant. DBCP bygger på en annan komponent i Jakarta Commons, nämligen ”Pool” som har tagit ett generellt grepp på själva ”poolningen”.
Digester
Parsning av XML dokument i Java är ofta en rörig historia där den traditionella SAX-parsern inte är speciellt enkel att tampas med. På slutet har dock en del nya APIer kommit i samband med Java Web Services Developer Pack. Ett alternativ till detta finns dock i Jakarta Commons-projektet, nämligen Digester. Digester är ett verktyg som mappar XML-dokument till Java-objekt. Det trevliga är att Digester är lätt att förstå sig på samtidigt som det är väldigt kraftfullt. Ett vanligt användningsområde för Digester är att hantera en applikations konfigurering i form av en XML-fil. För att använda Digester skapar man ett antal regler för hur Digester ska skapa objekt och sätta bean-properties från informationen i XML-filen. Struts använder Digester för att parsa sin struts-config.xml och instansierar internt upp så kallade ActionMapping-objekt som struts sedan använder internt för att mappa inkommande anrop till korrekt Action-instans. Här nedan har vi ett exempel på hur Digester kan användas för att parsa ett XML-dokument innehållande information kring en festlokal. Festlokalen består förutom ett par bean-properties av ett addressobjekt.
Följande XML-dokument ska behandlas:
<?xml version="1.0" encoding="ISO-8859-1"?>
<PartyLocation name="Ladan" capacity="250" kitchen="true" price="8000">
<Address name="PartyLadan" street="Storgatan 12" zip="123 45" city="Östersund"/>
</PartyLocation>
Koden som sätter upp parsningsregler och utför själva arbetet:
Digester digester = new Digester();
digester.setValidating(false); // Ingen DTD i exemplet...
// Regelsektion. Vi måste tala om för Digestern hur den ska göra.
// Hittas någon PartyLocation ska ett objekt enl. nedan skapas
digester.addObjectCreate( "PartyLocation", PartyLocation.class );
// Grundregel, prova att sätt alla beanproperties. OBS! Samma namn i fil och klass.
digester.addSetProperties("PartyLocation","*","*");
// Ifall namnen inte är samma i XML-fil och Java-klass kan man göra så här:
digester.addSetProperties("PartyLocation","kitchen","kitchenAvailable");
// Sedan skapas Address-objekt enl. nedan.
digester.addObjectCreate( "PartyLocation/Address", Address.class );
// Alla properties förs över från XML till objekt. Samma namn ett måste.
digester.addSetProperties("PartyLocation/Address","*","*");
// Här knyter vi ihop adressen med sitt PartyLocation-objekt.
digester.addSetNext("PartyLocation/Address","setAddress");
try {
FileInputStream fiStream = new FileInputStream("PartyLocation.xml");
// Här startar vi själva parsningen!
PartyLocation partyL = (PartyLocation)digester.parse(fiStream);
System.out.println(partyL);
fiStream.close();
} catch {}
Logging
Professionella Java-utvecklare har insett att loggning är en viktig del av en applikations liv. Inte bara i samband med felsökning under utveckling utan även som diagnostikverktyg under körning. I Java-världen finns idag en hel hög med olika loggningsimplementationer men de två dominerande är idag Log4J och JDK 1.4 loggnings-API. Val av loggningsimplementation är ofta ett huvudbry där ett projekt av olika anledningar vill använda sig av JDK 1.4 loggningen men samtidigt har projektet inte gått över från den tidigare JDK 1.3 till JDK 1.4. ”Commons Logging” är ett tunt skal som befriar den användande applikationen från beroendet till en viss loggningsimplementation. Genom en enkel konfigurering pekar man ut vilken loggningsimplementation som Commons Logging delegerar loggningen till. Två enkla implementationer ingår i paketet, SimpleLog och NoOpLog, vilket gör det enkelt att komma med loggning för ett projekt. Kodlistningen nedan visar ett enkelt exempel på användning.
public static Log log = LogFactory.getLog(PartyLocation.class);
public PartyLocation(String aName,
Address anAddress,
int aCapacity,
boolean aKitchenFlag,
double aPrice)
{
this.name = aName;
this.address = anAddress;
this.capacity = aCapacity;
this.kitchenAvailable = aKitchenFlag;
this.price = aPrice;
// Loggar skapandet av detta PartyLocation-objekt på debug-nivå.
log.debug("Skapar PartyLocation objekt: "+this.name);
// Vi kollar först att trace-nivå är aktiv så vi slipper
// skapa objekt som vi sedan inte behöver.
if (log.isTraceEnabled()) {
// Mer omfattande loggning på trace-nivå.
StringBuffer buf = new StringBuffer();
buf.append("Trace: ");
buf.append(" name=");
buf.append(this.name);
buf.append(" capacity=");
buf.append(this.capacity);
buf.append(" kitchen=");
buf.append(this.kitchenAvailable);
buf.append(" price=");
buf.append(this.price);
log.trace(buf.toString());
}
}
HTTP-Client
Java-plattformen innehåller i sin standardversion (Java 2 Standard Edition) en del grundläggande funktionalitet kring HTTP-kommunikation i paketet java.net. Tyvärr finns det en del funktioner i HTTP-protokollet som inte fullt stöds av grundpaketen i Java och här tillhandahåller projektet HTTP-Client det som saknas. Ska du bygga en egen webbläsare kan HTTP-Client vara en bra start.
Jelly
Jelly är ett skriptverktyg som genererar körbar kod från XML. Behöver du en skriptingmotor till ditt projekt kan Jelly vara intressant. Jelly går att integrera med Ant och kan använda sig av uttryck från JSTL (Java Standard Tag Library).
Net
Komponenten Net innehåller implementationer av ett antal klassiska internetprotokoll som till exempel Finger, Whois, TFTP, Telnet, POP3, FTP, NNTP, SMTP. Net härstammar från NetComponents (Tidigare utvecklat av ORO) som avstannade som projekt när ORO upplöstes. Exempel på användande projekt är Ant som använder Net för att tillhandahålla en telnet-task etc.
Validator
Hur många har inte utvecklat ett mer eller mindre bra ”Validerings-ramverk”? Gissningsvis sitter de flesta större organisationer på någon form av valideringsramverk som vuxit fast i affärslogik på olika sätt. Projektet Validator började som ett ”bidragsprojekt” till Struts för att sedan snabbt bli så populärt att det togs in i Struts 1.1 huvudutvecklingsspår. Validator bröts sedan ut igen till ett eget projekt under Jakarta Commons då man såg användningsområden utanför Struts-världen. Validator är en väldigt kompetent komponent som låter användaren definera valideringsregler deklarativt i en XML-fil. Det finns färdiga valideringsregler för ofta förekommande uppgifter samtidigt som Validators arkitektur möjliggör egna valideringsregler som kan göras internationaliserings-medvetna. Validator hanterat också dynamisk hantering av felmeddelanden.
Några andra intressanta projekt
BCEL
Källkodsfiler i Java kompileras till ett binärt ”.class”-filformat. Dessa filer innehåller ”maskinkod” för den virtuella maskinen som sedan kan exekveras på alla de operativsystem som VMen finns implementerad för. Denna maskinkod, som ofta bara kallas för ”bytekod”, kan analyseras och manipuleras med hjälp av BCEL (”Byte Code Engineering Library”).
Manipulera bytekoden är inte något som behövs i alla projekt, men BCEL kan vara ett ovärderligt hjälpmedel för att till exempel ta fram andra typer av utvecklingsverktyg. BCEL kan användas för att analysera tredjepartsbibliotek för att lista beroenden dem emellan, eller till och med introducera ny funktionalitet i befintliga klasser som du inte har källkoden till. Ett exempel på applikation där det kan vara viktigt är kompilatorer för aspektorienterad systemutveckling.
BSF
Avancerade program innehåller inte sällan ett skriptspråk för att avancerade användare ska kunna skriva små programsnuttar som styr och anpassar programmet på olika sätt. Ett känt exempel är de makron som finns i Word och Excel. När en applikationsprogrammerare står i begrepp att lägga till skriptmöjligheter i sitt program så uppkommer en viktig frågeställning: Vilket skriptspråk ska användaren få tillgång till?
Med hjälp av BSF (Bean Scripting Framework) kan svaret bli ”Java och JavaScript och Python (och… och…)”. BSF definierar nämligen ett ramverk för skriptspråk att integrera sig med, för att kunna kommunicera med Java-applikationer. Med hjälp av BSF och en implementation av ett skriptspråk som stödjer BSF kan du alltså välja och vraka bland alternativen. Exempel på skriptspråk som stödjer BSF på ett eller annat sätt är BeanShell (som är en skriptad variant av vanlig Java), Rhino (open source-implementation av JavaScript), JRuby (Java-implementation av Ruby) och JudoScript (något helt eget…).
En annan intressant aspekt av BSF är att det gör att dynamiska webbsidor (JSP-sidor) också kan använda sig av andra språk än Java, så länge det alternativ man väljer stödjer BSF.
James
Precis som Ant så har James ”tagit examen” från Jakarta och blivit ett eget projekt direkt under Apache. James är en ”e-postbaserad applikationsserver”, kan man säga. Den kan klara av det som en vanlig e-postserver klarar, det vill säga att skicka och ta emot e-postmeddelanden. Det som är intressant med James är dock att man dessutom kan skriva så kallade ”mailets” (namnet kommer naturligtvis från applets och servlets) som fungerar som plugin-moduler till servern, för att bygga e-postbaserade applikationer.
En mailet är ett objekt som lever i James, och blir tillsagd att utföra sina uppgifter när rätt händelser inträffar – typiskt förstås att ett e-postmeddelande kommer in som matchar ett angivet mönster. Mailet-instansen kan då inspektera meddelandet och göra sitt jobb.
Kodlistningen nedan är ett trivialt exempel som helt enkelt skriver ämnesraden till System.out för varje e-postmeddelande som kommer in.
import org.apache.mailet.;
public class SubjectLoggerMailet implements GenericMailet {
public void service(Mail mail) {
System.out.print("Ett nytt e-postmeddelande inkom med ämnet: ");
System.out.println(mail.getMessage().getSubject());
}
}
Bara för att leka med tanken lite så tänkte jag ge några förslag på vad man skulle kunna göra för typ av applikationer med mailets och James:
- E-postlistor – Meddelanden som går till en speciell adress skickas vidare till flera adressater i en lista. Med hjälp av en mailet kan listmedlemmar också automatiskt gå med i och gå ur en lista.
- Virus/spam-filter – Vissa meddelande läggs åt sidan för eventuell granskning innan de når adressaten.
- Fax/SMS-brygga – E-postmeddelanden skickas vidare till fax (i oförändrat skick) eller SMS (kanske bara rubriken i meddelandet).
- Informationsinhämtning – I en inbjudningstjänst som till exempel Fixafest.nu skulle man kunna låta gästerna skicka ett e-postmeddelande till en adress som motsvarade festen, där ”Rubrik”-raden skulle innehålla ”JA” respektive ”NEJ” om gästen kommer eller inte.
James klarar idag av de flesta relevanta standards (SMTP, POP3, etc) utom IMAP. Just avsaknaden av IMAP tycker i alla fall jag är väldigt synd eftersom James skulle ha varit den för mig perfekta all-round e-postservern om även IMAP fanns med. IMAP finns med på att-göra-listan och kommer att dyka upp så småningom, men som det är nu så är det framför allt de kraftulla mailet-funktionerna man ska vara ute efter om man vill använda James.
Log4J
En applikation som loggar på fel sätt kan snabbt få sin prestanda sänkt. Det kan vara frestande att skriva sitt egna loggningsramverk men i Java-världen finns det idag ingen anledning då vi redan har ett antal bra implementationer, där Log4J onekligen är det populäraste valet. Med Log4J är det möjligt att konfigurera ett antal loggningsnivåer under körning genom en konfigureringsfil. De nivåer som Log4J definerar är: ALL, DEBUG, INFO, WARN, ERROR, FATAL och OFF.
Genom att ärva från klassen org.apache.log4j.Level kan man utöka nivåerna ifall de inte passar. En kraftfull möjlighet med Log4J är att det hierarkiskt går att kontrollera vilka loggningsnivåer som är aktiva för olika Java-paket. Det går till exempel att under körning sätta loggningsnivån till INFO samtidigt som man låter ett specifikt paket logga med DEBUG-nivå. Förutom att det går att kontrollera vad som ska loggas finns en hel del olika sätt att definera på vilket sätt man vill att loggningen ska ske – allt ifrån filbaserad loggning till Unix syslog eller Windows Event Logger. Allt i Log4J konfigureras via en styrfil som antingen är i standard ”.properties”-format eller som en XML-fil.
Förutom valet av loggningskomponent är det minst lika viktigt att man bestämmer en loggningsstrategi, dvs en strategi kring hur loggning och framförallt loggningsnivå ska hanteras. Det finns andra viktiga detaljer kring hur man med enkla medel kan bibehålla god prestanda trots att man tillhandahåller omfattande loggning i applikationen. Loggning är ett stort och viktigt ämne som vi säkert får anledning att återkomma till.
Lucene
Generella sökverktyg på internet som till exempel Google visar sin styrka dagligen när du är ute efter information. Med hjälp av Lucene kan du bygga in motsvarande funktionalitet i ditt egna system.
Lucene är en motor för fritextindexering och -sökning som lätt integreras i ditt system. Hur viktigt detta kan vara för din applikation beror förstås på vilken typ av system det är. Om du hanterar stora mängder textinformation och dokument av olika slag har du säkert mycket att vinna på en funktion för fritextsökning.
OJB
OJB (ObjectRelationalBridge) är, som namnet antyder, ett verktyg som låter dig som utvecklare använda dig av ett objektdatabasgränssnitt mot en vanlig relationsdatabas. Jag tänker inte här på något sätt ge mig in på att beskriva för- och nackdelar med objektdatabaser respektive relationsdatabaser, utan förutsätter att läsaren har ett hum om detta.
Det bästa med OJB är att det inte hittar på ytterligare ett eget databas-API, utan erbjuder ett API som fullt ut stödjer ODMG 3.0, och dessutom JDO, som är Suns standard-API för objektdatabaser. Mappningen mellan Java-klasser och tabeller i relationsdataser ligger i XML-filer som beskriver sambanden. OJB innehåller också verktyg för att generera dessa mappningar, och tabellerna eller klasserna (beroende på vilket håll man kommer ifrån) som används.
Vissa typer av applikationer lämpar sig väl för att använda relationsdatabaser med väldefinierade tabeller, medan andra inte alls gör det. I de fallen är objektdatabaser väldigt kraftfulla verktyg. Med hjälp av OJB kan du använda din favoritdatabas i båda dessa fall.
POI
Det första sätt som POI utmärker sig på är kanske lite oväntat: de har den absolut fyndigaste akronymen! POI står för ”Poor Obfuscation Implementation”, det vill säga ungefär ”dåligt fördunklad implementation”. Vad de syftar på då är Microsofts OLE2-filformat, som används av till exempel Microsoft Word.
Projektet POI innehåller alltså ett bibliotek som gör det möjligt för rena Java-program att läsa och skriva filer för i första hand Microsoft Word och Excel. Det är alltså inte ”tabbseparerade textfiler” man syftar på, utan ”riktiga” Office-filer. Vare sig man gillar det eller inte så är Microsoft Office det absolut dominerande programpaketet för ordbehandling och kalkylprogram. POI kan alltså komma väl till pass när man vill importera eller exportera information mellan Microsoft Office och ett eget system.
Kodlistningen nedan visar ett exempel som skapar en enkel Excel-fil.
HSSFWorkbook wb = new HSSFWorkbook();
HSSFSheet sheet = wb.createSheet("new sheet");
HSSFRow row = sheet.createRow((short)0);
HSSFCell cell = row.createCell((short)0);
cell.setCellValue(1);
row.createCell((short)1).setCellValue(1.2);
row.createCell((short)2).setCellValue("Hej på dig!");
row.createCell((short)3).setCellValue(true);
FileOutputStream fileOut = new FileOutputStream("POI_exempel.xls");
wb.write(fileOut);
fileOut.close();
Slutord
Att vara en framgångsrik systemutvecklare handlar mycket om att välja rätt verktyg för uppgiften. Det svåra är dock att känna till alla verktyg man har till sitt förfogande. Vi hoppas att den här artikeln har gett en inblick i en del av den uppsättning hjälpmedel som står till buds för Java-utvecklare. Naturligtvis finns det mångdubbelt fler intressanta open source-projekt utanför Apache-paraplyet, men vi tycker att Apache är ett bra ställe att börja på när man ska bekanta sig med alternativen i Java-världen.